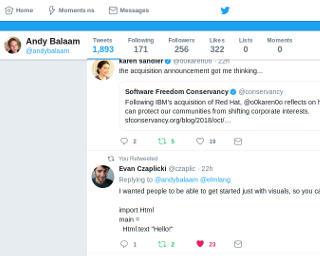
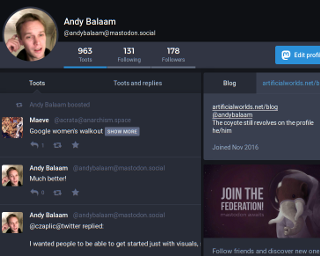
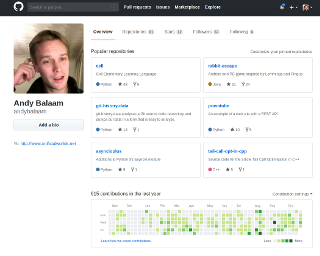
Concepts









Character: 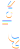 U+012F LATIN SMALL LETTER I WITH OGONEK U+0307 COMBINING DOT ABOVE U+0301 COMBINING ACUTE ACCENT
UTF-8: C4 AF CC 87 CC 81 11000100 10101111 11001100 10000111 11001100 10000001
UTF-16BE: 01 2F 03 07 03 01 00000001 00101111 00000011 00000111 00000011 00000001
UTF-16LE: 2F 01 07 03 01 03 00101111 00000001 00000111 00000011 00000001 00000011
UTF-32: 00 00 01 2F 00 00 03 07 00 00 03 01 00000000 00000000 00000001 00101111 00000000 00000000 00000011 00000111 00000000 00000000 00000011 00000001
US-ASCII: - - - 00111111 00111111 00111111
ISO-8859-1: - - - 00111111 00111111 00111111
ISO-8859-7: - - - 00111111 00111111 00111111
GB18030: 81 30 90 31 81 30 BD 33 81 30 BC 37 10000001 00110000 10010000 00110001 10000001 00110000 10111101 00110011 10000001 00110000 10111100 00110111
Shift_JIS: - - - 00111111 00111111 00111111
GSM_0338: - - - 00111111 00111111 00111111
EBCDIC 1047: - - - 00111111 00111111 00111111
U+012F LATIN SMALL LETTER I WITH OGONEK U+0307 COMBINING DOT ABOVE U+0301 COMBINING ACUTE ACCENT
UTF-8: C4 AF CC 87 CC 81 11000100 10101111 11001100 10000111 11001100 10000001
UTF-16BE: 01 2F 03 07 03 01 00000001 00101111 00000011 00000111 00000011 00000001
UTF-16LE: 2F 01 07 03 01 03 00101111 00000001 00000111 00000011 00000001 00000011
UTF-32: 00 00 01 2F 00 00 03 07 00 00 03 01 00000000 00000000 00000001 00101111 00000000 00000000 00000011 00000111 00000000 00000000 00000011 00000001
US-ASCII: - - - 00111111 00111111 00111111
ISO-8859-1: - - - 00111111 00111111 00111111
ISO-8859-7: - - - 00111111 00111111 00111111
GB18030: 81 30 90 31 81 30 BD 33 81 30 BC 37 10000001 00110000 10010000 00110001 10000001 00110000 10111101 00110011 10000001 00110000 10111100 00110111
Shift_JIS: - - - 00111111 00111111 00111111
GSM_0338: - - - 00111111 00111111 00111111
EBCDIC 1047: - - - 00111111 00111111 00111111